New Mobility Modeller
The New Mobility Modeller (NMM) is a choice model used to calculate the travel mode choices of trips between Origin-Destination (OD) pairs based on socio-economics (i.e. income, ownership of a drivers license , age, student public transport (PT) card and ownership of car) and mode-specific attributes like travel time, amongst others.
The NMM is developed to calculate the mode choice within the four-step modelling framework. However, it is important to note that the model uses the existing attraction and production potential at zonal level and recalculates the demand based on modal and socio-economic population characteristics. Attraction/ Production potential per zone referes to the total trips that can be attracted to or produced from a zone. The underlying principle used here is the discrete choice modelling method- The Multinominal Logit Model (MNL). As indicated by its name, the mode choices include not only the traditional travel modes (car, PT, bike and walk) but also the new mobility concepts, including automated vehicles, automated (shared) taxis, and automated shared vans, provided we have the relevant dataset. Besides, new parking concepts, i.e., automated-valet Parking, are also included since they affect mobility choices. The model is implemented using the state-of-art parallel computing technology CUDA to be capable of running many scenarios/iterations on a large-scale road network within a reasonable time duration.
Overview of computation steps
To represent the attractiveness of the alternatives, the concept of utility (which is a convenient theoretical construct defined as what the individual seeks to maximize) is used. Alternatives, per se, do not produce utility: this is derived from their characteristics and those of the individual; for example, the observable utility is usually defined as a linear combination of variables where each variable represents an attribute of the option or the traveler. The relative influence of each attribute, in terms of contributing to the overall satisfaction produced by the alternative, is given by its coefficient. The variables can also represent characteristics of the individual. The alternative-specific constant, is normally interpreted as representing the net influence of all unobserved, or not explicitly included, characteristics of the individual and the option in its utility function. For example, it could include elements such as comfort and convenience which are not easy to measure or observe. To predict if an alternative will be chosen, according to the model, the value of its utility must be contrasted with those of alternative options and transformed into a probability value between 0 and 1.
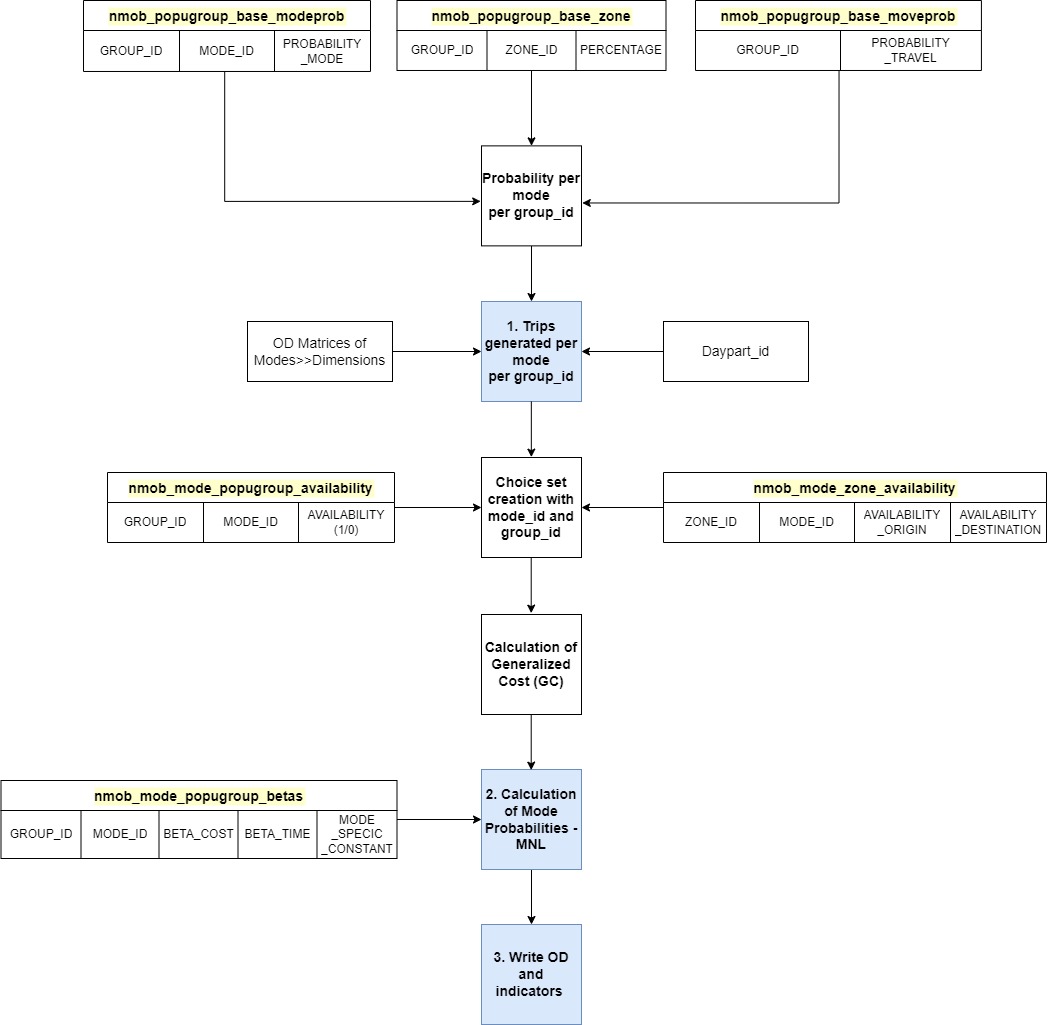
The NMM framework within Urban Strategy is based on three main components:
- Travel Demand generation – Obtain the total trips (demand) for each population group, for each OD-pair
- Mode Check and Utility computation – Calculate the mode choice proportions per population group for each OD pair.
- Write output and Indicators
The Multinominal Logit Model (MNL) - Expert User Level
Travel Utility computation in NMM is based on the Multi Nominal Logit (MNL) Model. This is still the popular practical discrete choice model. It can be generated assuming that the error term are Gumbel distributed (also called Weibull). With this assumption the choice probabilities are calculated as follows:
Here the \(V_{i}\) represents the utility of an alternative \(i\), within an alternatives set \(A\). In NMM, the MNL is used in performing a modal split based on the mode specific parameters and population group characteristics (car ownership, availability of driver's license, income group, age group and availability of public transport card). The first step in this case is to calculate the utility per alternative (Mode and group id), with the \(\beta\) being the utility parameters. The Utility function is basically the Generalized Cost (GC) function per mode and population group for the NMM. The Utility function used is devoid of random terms. Therefore the choice proportions are completely deterministic (different iterations will provide the same choice proportions with the same input parameter setup). The formulation for GC used in NMM is as provided below:
where:
- \(V_{mode,group}\):the "util" of a specific mode and group combination
- \(ASC_{mode,group}\) is the Alternate specific Constant per mode and per group.
- \(\beta_{time}\) is the scalar weight of the attribute: Time
- \(\beta_{cost}\) is the scalar weight of the attribute: travel cost. Value obtained from nmob_mode_popugroup_betas
- \(TIME\) = \((T_{SearchVehicle} + T_{ivt}) \cdot ExtraTimeFactor + T_{ParkingSearch}\). The unit is hours.
- \(T_{ivt}\) = the skim in vehicle travel time (reference or actual) for the mode and OD pair, obtained from the traf-odmatrix-3 collection.
- \(T_{SearchVehicle}\) = Time obtained from Traf-modes collection for finding a mode before a travel, as is the case with a shared car or shared bike. The time is in minutes, which should be converted to hours when used.
- \(extraTimeFactor\) = Factor multiplied for a particular mode to incorporate travel time factor (between 1 and 0). Obtained from traf-modes collection
- \(T_{ParkingSearch}\) = \(Proportion_{pal} \cdot T_{pal}\) + \(Proportion_{avp} \cdot T_{avp}\) + \(Proportion_{pjo} \cdot T_{pjo}\)
- PAL – Parking at Location, AVP – Automated Valet Parking, PJO – Parking just outside. These considerations of different parking option increase the accuracy of the Time associated with Parking (to consider the effect of walking from parking lot to destination).
- \(COST\) = \(CostStart+ (TravelDistance \cdot CostUser)+ParkingCost\)
- \(CostStart\) = Cost associated with the choice of a travel mode, not including the actual km usage. Such as car/bike rental fee or ticket price excluding km usage, etc. Obtained from traf_modes collection
- \(TravelDistance\) = the skim travel distance (reference or actual) for the mode and OD pair, obtained from the traf_odmatrix_3 collection.
- \(CostUser\) = Cost associated with the KM usage of the travel mode. It could be the Km usage of a public transport mode or that of a shared bike or car. Obtained from traf_modes collection
- \(ParkingCost\) = \(Proportion_{pal} \cdot Cost_{pal}\) + \(Proportion_{avp} \cdot Cost_{avp}\) + \(Proportion_{pjo} \cdot Cost_{pjo}\)
The proportions are then used to calculate the "New" demand per OD pair. This forms the final output of the NewMM, apart from the indicators (see Output).
Furthermore, it is important to make note of the subsidiary input data collections, which provide information regarding the mode-id/group-id availability at the zonal level. They are as provided below:
- nmob-mode-popugroup-availability
- nmob-mode-popugroup-betas
- nmob-mode-zone-availability
- nmob-mode-popugroup-base-modeprob
- nmob-mode-popugroup-base-moveprob
- nmob-mode-popugroup-base-zone
Interaction of the input data and model - Expert User Level
The relationship between the input provided in these collections and the probability calculation is provided. NMM function requires dataset on the socio-demographic characteristics of the demand, categorized per mode. As for the trip generation components, the input collections used are: nmob-mode-popugroup-base-modeprob, nmob-mode-popugroup-base-moveprob and nmob-mode-popugroup-base-zone. The probability of travel per mode, per population group is obtained from these collection, which are then multiplied on the OD demand to identify the choice set (demand per mode-id and group-id). Once these OD matrices are computed per mode-id and group-id, the next step would be to calculate the utility per alternative. The nmob-mode-popugroup-availability and nmob-mode-zone-availability collections ensure the availability of the modes at a particular zone, categorized at origin and destinations. The nmob-mode-popugroup-betas collections provide the Beta values and Mode-specific-constant for the mode/group alternative. These are then used to calculate the generalized cost and corresponding choice proportions. The final step is to calculate the date required for the output collections.
Output
In the overview below we describe where the output of the model can be found in the data.
| Description | Location |
|---|---|
| Change in Trips at OD pair | The newly calculated change in each Origin-Destination matrix is the main output of NMM. It can be found in column -DeltaTripsNewMM-, within traf-odmatrix |
| Modal split | The overall percentage share of different modalities. This can be found in nmob-indic-dat5 |
| Trip kilometers per mode | The product of trips and the travel distance per OD pair for all the available travel modalities. This output can be found in nmob-indic-dat7 |
| Parking count per parking option type | the amount of cars at different parking types - Parking at location, automatic valet parking and Parking just outside. The output values can be found in nmob-indic-dat10 |
Parameters and settings
| Parameter Name | Description | Type | Default |
|---|---|---|---|
| logitParam | The β parameter is used in the calculation probability in MNL model | Float | -0.5 |
| RD_originfactor | Indicating how much people in rest of day time period are departing from their home address (opposed to arriving to their home address) | Float | 0.5 |
| write_od | Flag to indicate whether to update OD matrix | Boolean | false |
| OD update threshold | The minimal difference needed between the input OD matrix trips and NMM output for the NMM to write to the store | Float | 1 |
| Day Part | Day period, Choose from | String | - |
| Max iterations with Traffic model | Maximum number of iterations to prevent endless loop between NMM and traffic+/PT module, when all these are run in parallel | Integer | 2 |
| Pivot | Enable pivot method for the NMM output | Boolean | True |
| CalibrationRun | Calculate the calibration values for the pivot method, will automatically shutdown after the calculation | Boolean | False |
| Distribution Parking At Location | Parking distribution (used when distribution values in traf_zones are not added to 100%) | Integer (0-100) | 30 |
| Distribution Parking Automated Valet | Parking distribution (used when distribution values in traf_zones are not added to 100%) | Integer (0-100) | 35 |
| Distribution Parking Outside Buildup Area | Parking distribution (used when distribution values in traf_zones are not added to 100%) | Integer (0-100) | 35 |
Example parameter JSON
The JSON below can be used in the parameters key-value set in the store editor to configure the Traffic model. You can use the button in the corner to copy the JSON to your clipboard.
[{"Name":"logitParam","Value":-0.5,"Type":2},{"Name":"Distribution Parking At Location","Value":100,"Type":1},{"Name":"Distribution Parking Automated Valet","Value":0,"Type":1},{"Name":"Distribution Parking Outside Buildup Area","Value":0,"Type":1},{"Name":"write_od","Value":"1","FreeEdit":false,"Selection":["0","1"],"Unit":"write od to store (or not)"},{"Name":"Day part","Value":"Morning peak","FreeEdit":false,"Selection":["Morning peak","Evening peak","Rest of day"]},{"Name":"Rd_originfactor","Value":0.5,"Type":2,"Unit":""},{"Name":"Max iterations with Traffic model","Value":2,"Type":1},{"Name":"Pivot","Value":true,"Type":3},{"Name":"CalibrationRun","Value":false,"Type":3}]
Literature
For more details on four steps and mode choice modelling we refer to the following book on Transport Modelling:
- Ortúzar & Willumsen (2011). Modelling Transport, 4th Edition, Oxford, United Kingdom: John Wiley and Sons, Ltd
also referring to a paper on the concepts of NMM used in the Digital Twin Platform:
- Snelder, M., Wilmink, I., Gun, J. v., Bergveld, H. J., Hoseini, P., & Arem, B. v. (2019). Mobility impacts of automated driving and shared mobility - explorative model and case study of the province of north-Holland. ETJIR, 19(4), 291-309.